 |
| The Golem, by Philippe Semeria |
(Part One)
This is the second (and final) part in my series looking at the arguments from Muehlhauser and Helm’s (MH’s) paper “The Singularity and Machine Ethics”.
As noted in part one, proponents of the Doomsday Argument hold that if a superintelligent machine (AI+) has a decisive power advantage over human beings, and if the machine has goals and values that are antithetical to the goals and values that we human beings think are morally ideal, then it spells our doom. The naive response to this argument is to claim that we can avoid this outcome by programming the AI+ to “want what we want”. One of the primary goals of MH’s paper is to dispute the credibility of this response. The goal of this series of blog posts is to clarify and comment upon the argument they develop.
Part one accomplished most of the necessary stage-setting. I shan’t summarise its contents here. Instead, I simply note that we ended the previous post by adopting the following formulation of the naive response to the Doomsday Argument.
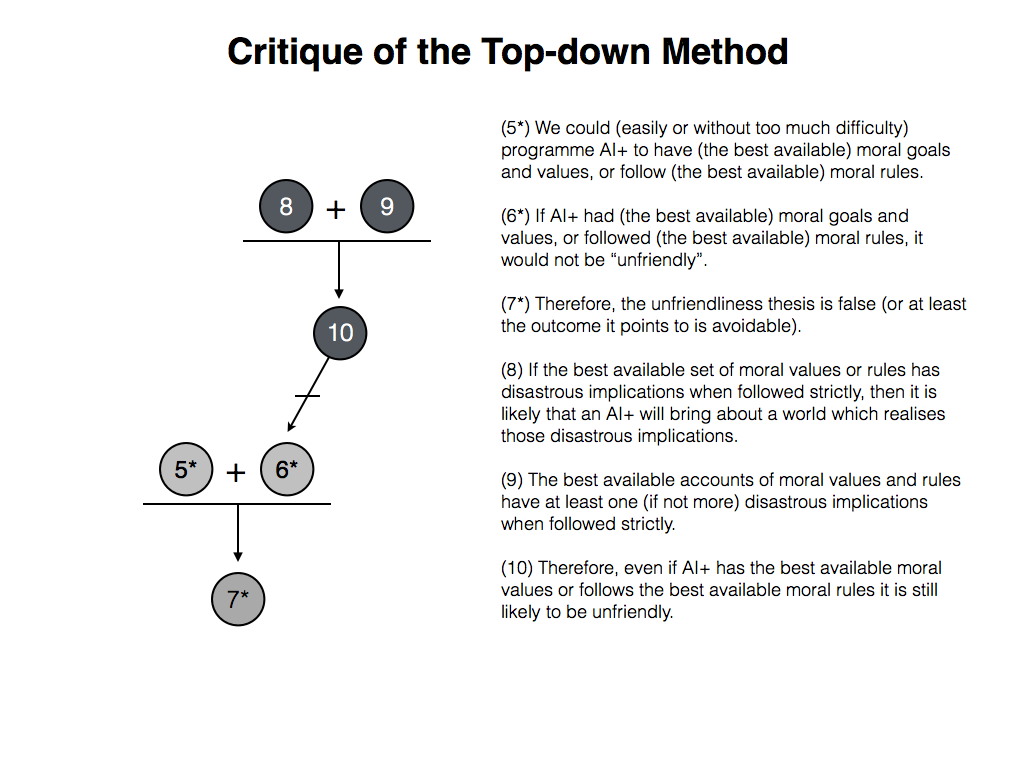
- (5*) We could (easily or without too much difficulty) programme AI+ to have (the best available) moral goals and values, or follow (the best available) moral rules.
- (6*) If AI+ had (the best available) moral goals and values, or followed (the best available) moral rules, it would not be “unfriendly”.
- (7*) Therefore, the unfriendliness thesis is false (or at least the outcome it points to is avoidable).
While this argument is more elaborate than the one presented in MH’s paper, I argued in part that it is preferable for a number of reasons, including the fact that it still retains an air of naivete. The naivete arises out of the two core premises of the argument, i.e. the claim that it would be “easy” to program AI+ to adopt the best available set of moral goals or follow the best available set of moral rules, and the claim that the best available set of moral goals and rules would not be “unfriendly” (where this must be understood to mean “would not lead to disastrous or unwelcome consequences”). MH dispute both claims. They do so by thinking about the two methods AI researchers could use to ensure that the AI+ has a set of moral values or follows a set of moral rules. They are:
The Top-Down Method: The AI researcher directly programmes the values and rules into the AI+. In other words, the researcher painstakingly codes into the AI+ the optimization algorithm(s) which represent the best available conception of what is morally valuable, or codes the AI+ to follow the best available and fully-consistent set of moral rules.
The Bottom-up Method: A sophisticated learning machine with basic goals is created, which is then encouraged to learn moral values, goals and rules on a case-by-case basis (*roughly* similar to how humans do it).
As MH see it, thinking about the plausibility of the first method will call premise (6*) of the naive response into doubt; and thinking about the plausibility of the first method will call premise (5*) into doubt.
In the remainder of this post, I want to consider both of these arguments. I start by addressing MH’s critique of the top-down method, and follow this by considering their critique of the bottom-up method. I close with some general comments about standards of success of philosophical argumentation and their connection to the study of AI+. I do so because reflecting on MH’s arguments (particularly the first one) raises this issue in my mind.
1. The Counterexample Problem and the Top-Down Method
In critiquing the top-down method, MH highlight a common and annoying feature of philosophical argumentation. Take any particular phenomenon of philosophical interest, for example, causation (MH pick knowledge initially but hey what’s wrong with a little variation?).
How does philosophical research about a phenomenon like causation proceed? Typically, what happens is that some philosopher will propose an account or analysis of “causation”. That is to say, they will try to identify exactly what it is that makes one event cause another (say, temporal precession). This account will get tossed about by the philosophical community and, invariably, along will come another philosopher who will pose a counterexample to that particular account. Thus, they will identify a case in which A does not temporally precede B, but nevertheless it is clearly the case that event A is causing B. This might result in a new account of causation being developed, which will in turn be challenged by another counterexample. The process can cycle on indefinitely.
This pattern is common to many fields of philosophical inquiry including, most disconcertingly, philosophical attempts to identify the best available moral values and rules. So, for example, a philosopher will start, often with great enthusiasm, by developing an account of the “good” (e.g. conscious pleasure). This is batted around for a while until someone comes up with a counterexample in which the maximisation of conscious pleasure actually looks to be pretty “bad” (e.g. Nozick’s experience machine argument). This leads to a newer, more refined and sophisticated account of the good, which is then in turn knocked down by another counterexample.
MH exploit this common feature of philosophical argumentation in their critique of the top-down method. For when you think about it, what would an AI programmer have to do when programming an AI+ with a set of moral values or rules? Well, if they wanted to get the “best available” values and rules, presumably they’d have to go to the moral philosophers who have been formulating and refining accounts of moral values and rules for centuries now. They would then use one or more of these accounts as the initial seed for the AI+’s morality. But if every account we’ve developed so far is vulnerable to a set of counterexamples which show that abiding by that account leads to disastrous and unwelcome outcomes, then there is a problem. AI+ will tend to pursue those values and follow those rules to the letter, so it becomes highly likely (if not inevitable) that they will bring about those disastrous consequences at some point in time.
That gives us all we need to formulate MH’s first argument against the naive response, this one being construed as a direct attack on premise (6*):
- (8) If the best available set of moral values or rules has disastrous implications when followed strictly, then it is likely that an AI+ will bring about a world which realises those disastrous implications.
- (9) The best available accounts of moral values and rules have at least one (if not more) disastrous implications when followed strictly.
- (10) Therefore, even if AI+ has the best available moral values or follows the best available moral rules it is still likely to be unfriendly.
I’m going to look at MH’s defence of premise (9) in a moment. Before doing that, it’s worth commenting briefly on the defence of premise (8). I’ve adumbrated this already, but let’s make it a little more explicit. The defence of this premise rests on two assumptions about the properties that AI+ are likely to have. The properties are: (a) literalness, i.e. the AI+ will only recognise “precise specifications of rules and values, acting in ways that will violate what feels like “common sense” to humans” (MH, p. 6); and (b) superpower, i.e. the AI+ will have the ability to achieve its goals in highly efficient ways. I have to say, I don’t know enough about how AI is in fact programmed to say whether the literalness assumption is credible, and I’m not going to question the notion of “superpower” here. But it is possible that these assumptions are misleading. I haven’t read all of his work on this topic, but Alexander Kruel suggests in some of his writings that arguments from the likes of MH (where “likes of” = “members of research institutes dedicated to the topic of AI risk”) tend to ignore how AI programming is typically carried out and thus tend to overstate the risks associated with AI development. I’m not sure that this critique would directly challenge the literalness assumption, but it might suggest that any AI which did counterintutive things when following rules would not be developed further. Thus, the risks of literalness are being overstated.
2. Do all moral theories have (potentially) disastrous implications?
Let’s assume, however, that premise (8) is fine. That leaves premise (9) as the keystone of the argument. How does it stack up? The first thing to note is that it is nigh on impossible to prove that every single account of moral values and rules (that has been or might yet be) is vulnerable to the kinds of counterexamples MH are alluding to. At best, one can show that every theory that has been proposed up until now is vulnerable to such counterexamples, but even that might be asking too much (especially since MH want to be optimistic about the potential of ideal preference theories). So examining a representative sample of the theories that have been proposed to date might be more practical. Further, although it wouldn’t provide rock-solid support for premise (9), doing so might provide enough support to make us think that the naive response is indeed naive, which is all we really wanted to do in the first place.
Unsurprisingly, this is what MH do. They look at a few different examples of utilitarian accounts of moral value, and show that each of these accounts is vulnerable to counterexamples of the sort discussed above. They then look (more generally) at rule-based moral theories, and show how these could have several implementation problems that would lead to disastrous consequences. This provides enough basic support for premise (9) to make the naive response look sufficiently naive. I’ll briefly run through the arguments they offer now, starting with their take on hedonic utilitarianism.
Hedonic utilitarianism holds, roughly, that the most valuable state of being is the one in which conscious pleasure is maximised (for the maximum number of people). Although this theory is vulnerable to a number of well-known counterexamples — e.g. Parfit’s repugnant conclusion or Nozick’s experience machine — MH note a very important problem with it from the perspective of AI programming. The term “pleasure” lacks specificity. So if this account of moral values is going to be used to seed an AI+’s morality, the programmer is going to have to specify exactly what it is that the AI+ should be maximising. How might this pan out? Here are two possible accounts of pleasure which have greater specificity. In discussing each, counterexamples which are consistent with those accounts will be presented:
Pleasure gloss theory: According to MH, the growing consensus in neurobiology is that what we refer to as pleasure is not actually a sensation, but rather a gloss added to our sensation patterns by additional brain activity. In essence, pleasure is something that the brain “paints” onto sensations. What kinds of counterexamples would this account of pleasure be vulnerable to? MH suggest that if pleasure can simply be painted onto any sensations whatsoever, an AI+ might be inclined to do this rather than seek out sensations that are typically thought to be pleasurable. This could by hooking them up to some machines or implanting them with nanotechnology that activates the relevant “pleasure painting” areas of the brain, in a scenario much like Nozick’s experience machine. This would be a logically consistent implication of the hedonic theory but an unwelcome one.
Reward Signal Theory: Alternatively, one could specify that pleasure is anything that functions as a reward signal. Would that create problems? Well, if reward signals can be implemented digitally or mechanically, the AI+ might simply manufacture trillions of digital minds, and get each one to run its reward signal score up to the highest possible number. This would achieve the goal of maximises hedonic pleasure.
So adding specificity can still lead to disastrous consequences for hedonic utilitarianism. Not a particularly surprising conclusion given the general status of such theories in moral philosophy, but one worth spelling out in any event.
How about negative utilitarianism, which holds that instead of maximising conscious pleasure one should minimise suffering, is that vulnerable to counterexamples as well? Presumably, there are specification problems to be dealt with here again, but more generally the problem is that the quickest route to the minimisation of suffering would seem to be to kill all humans. After all, no humans means no suffering. An AI+ might be inclined to follow the quickest route. But wait, couldn’t this be avoided by simply adding an exception clause to the AI+’s program stating that that the AI+ should minimise suffering, provided doing so doesn’t involve killing humans? Maybe, but that would run into the difficulties faced by rule-based theories, which I’ll be talking about in a moment.
The final utilitarian theory addressed by MH is preference/desire utilitarianism. According to this theory, the goal should not be to maximise conscious pleasure but, rather, to maximise the number of human preferences/desires that are satisfied. Would this run into problems? MH say it would. According to several theories, desires are implemented in the dopaminergic reward system in the human brain. Thus, one way for an AI+ to achieve the maximum level of desire satisfaction would be to rewire this system so that desires are satisfied by lying still on the ground.
Isn’t that a little far-fetched? MH submit that it isn’t, certainly no more far-fetched than suggesting that the AI+ would achieve the maximum level desire satisfaction by created a planet-wide utopia by satisfying the desires that humans actually have. This is for two reasons. First, individual human beings have inconsistent preferences, so it’s not clear that this could maximised desire-satisfaction could be implemented at an individual level without some re-wiring. Second, humans interact in “zero sum” scenarios. This means it will not be possible to satisfy everybody’s desires (e.g. as when two people have the desire to win some competition that can only have one winner). This makes the “lying still on the ground” scenario more plausible.
That’s all MH have to say about utilitarian theories of value. What about rule-based accounts of morality? Do they fare any better? Without discussing specific examples of rule-based accounts, MH identify several general problems with such accounts:
- If there are several rules in the theory, they can conflict in particular cases thereby leading to at least one being broken.
- The rules may fail to comprehensively address all scenarios, thereby leading to unintended (and unknown) consequences.
- An individual rule might have to be broken in a particular case where the machine faces a dilemmatic choice (i.e. a choice in which it must, by necessity, break the rule by opting for one course of action over another).
- Even if a set of rules is consistent, there can be problems when the rules are implemented in consecutive cases (as allegedly shown in Petit 2003).
- Rules may contain vague terms that will lead to problems when greater specificity is added, e.g. the rule “do not harm humans” contains the vague term “harm”. These are similar to the problems mentioned above with respect to hedonic utilitarian theories.
- If the rules are external to the AI+’s goal system, then it is likely to exploit loopholes in the rules in order to make sure it can achieve its goals (much like a lawyer would do only to a greater degree).
Thus, the claim is that rule-based theories are vulnerable to the same kinds of problems as value-based theories. Although I accept this basic idea, I think some of these problems are less concerning than others. In particular, I do not really think the fact that an AI+ might face a moral dilemma in which it has to break a moral rule is problematic. For one thing, this might simply lead to a Buridan’s Ass type of situation in which the machine is unable to decide on anything (those more knowledgeable about AI can correct me if I’m wrong). Or, even if there is some trick used to prevent this from happening and the AI+ will follow one course of action, I do not see this as being morally concerning. This is because I think that in a true moral dilemma there is no wrong or right course of action, and thus no way to say we would be better off following one course of action or another.
3. The Critique of the Bottom-up Method
So much for MH’s critique of the top-down method. We can now consider their critique of the bottom-up method. As you recall, the bottom-up method would require the AI+ to learn moral values and rules on a case-by-case basis, presumably a method that is somewhat analogous to the one used by human beings. Superficially, this might seem like a more reassuring method since we might be inclined to think that when rules and values are learned in this way, the machine won’t act in a counterintuitive or unexpected manner.
Unfortunately, there is no good reason to think this. MH argue that when a machine tries to learn principles and rules from individual cases, we can never be 100% sure that they are extrapolating and generalising the “right” rules and principles. In support of this contention, they cite a paper from Dreyfus and Dreyfus (notorious critics of AI) published back in 1992. In the paper, Hubert and Stuart Dreyfus cite a case in which the military tried to train an artificial neural network to recognise a tank in a forest. Although the training appeared, on initial tests, to be a success, when the researchers tried to get the network to recognise tanks in a new set of photographs, it failed. Why was this? Apparently, the system had only learned to recognise the difference between a network with shadows and without; it had not learned to recognise tanks. The same problem, MH submit, could apply to learning moral values and rules: unless they are explicitly programmed into the AI, we can never be sure that they have been learned.
In addition to this problem, there is the fact that a superintelligent and superpowerful machine is likely to bring about states of affairs which are so vastly different from the original cases in which it learned its values and rules that it will react in unpredictable and unintended ways. That gives us this argument:
- (11) If an AI+ learns the wrong moral values and rules from the original set of cases it is presented with, or if it is confronted with highly disanalogous cases, then unintended, unpredictable, and potentially disastrous consequences will follow.
- (12) It is likely (or certainly quite possible) that an AI+ will learn the wrong values and rules from the original set of cases, or will bring about states of affairs that are vastly different from those cases.
- (13) Therefore, even if AI+ learns moral values and goals on a case-by-case basis, it is likely that unintended, unpredictable, and potentially disastrous consequences will follow.

I haven’t got too much to say about this argument. But three brief comments occur to me. First, the argument is different from the previous one in that it focuses more on the general uncertainty that arises from the bottom-up method, not on particular hypothetical (but logically consistent) implications of the best available moral values and rules. Second, I don’t really know whether this is a plausible argument because I don’t know enough about machine learning to say whether the problems highlighted by Dreyfus and Dreyfus are capable of being overcome. Third, elsewhere in their article, MH discuss the fact that human brains have complex, sometimes contradictory, ways of identifying moral values and following moral rules. So even if we tried to model an AI+ directly on the human brain (e.g. through whole-brain emulation), problems are likely to follow.
4. Conclusion
To sum up, the naive response to the Doomsday Argument is to claim that AI+ can be programmed to share our preferred moral values or to follow moral rules. MH argue that this response is flawed in two main respects. First, there is the problem that many of our moral theories have disastrous implications in certain scenarios, implications that an AI+ might well be inclined to follow because of their literal mindedness. Second, there is the problem that training AI+ to learn moral values and rules on a case-by-case basis is likely to have unintended and unpredictable consequences.
One thing occurred to me in reading all this (well, several things actually but only one that I want to mention here). This has to do with standards of success in philosophical argumentation and their applicability to debates about friendly and unfriendly AI. As many people know, philosophers tend to have pretty high standards of success for their theories. Specifically, they tend to hold that unless the theory is intuitively compelling in either all logically, metaphysically or physically possible worlds, it is something of a failure. This is why supposedly fatal counterexamples are so common in philosophy. Thus, an account of knowledge is posed, but it is found not to account for knowledge in certain possible scenarios, and so the account must be refined or abandoned.
Advocates of the Doomsday Argument employ similarly high standards of success in their discussions. They tend to argue that unless disastrous consequences for an AI+ can be ruled out in all (physically) possible worlds, the Doomsday Argument is correct. This means they rely on somewhat farfetched or, at least, highly imaginative hypotheticals when defending their view. We see this to some extent in MH’s first argument against the naive response. But the question arises: Are they right to employ those high standards of success?
I think I can see an argument in favour of this — roughly: since an AI+ will be vastly powerful it might be able to realise all physically possible worlds (eventually); so we have to make sure it won’t do anything nasty in all physically possible worlds — but I’d like to leave you with that question since I believe it’s something that critics of the Doomsday Argument tend to answer in the negative. They charge the doom-mongers with being too fanciful and outlandish in their speculations; not grounded enough in the realities of AI research and development.
No comments:
Post a Comment