
(Previous Entry)
There is no denying that improvements in technology allow machines to perform tasks that were once performed best by humans. This is at the heart of the technological displacement we see throughout the economy. The key question going forward is whether humans will maintain an advantage in any cognitive or physical activity. The answer to this question will determine whether the future of the economy is one in which humans continue to play a relevant part, or one in which humans are left behind.
To help us answer this question it is worth considering the paradoxes of technological improvement. It is truly amazing that advances in artificial intelligence have allowed machines to beat humans at cognitive games like chess or Jeopardy!, or that cars can now be driven around complex environments without human assistance. At the same time, it is strange that other physical and cognitive skills have been less easy for machines to master, e.g. natural language processing or dextrous physical movements (like running over rough terrain). It seems paradoxical that technology could be so good at some things and so bad at others.
Technologists and futurists have long remarked on these paradoxes. Moravec’s paradox is a famous example. Writing back in the late 80s, Hans Moravec (among others) noted the oddity in the fact that high-level reasoning took relatively few computational resources to replicate, whereas low-level sensorimotor skills took far more. Of course, we have seen exponential growth in computational resources in the intervening 30 years, so much so that the drain on computational resources may no longer be an impediment to machine takeover of these tasks. But there are other problems.
This brings us to the (very closely related) ‘Polanyi’s Paradox’, named in honour of the philosopher and polymath Michael Polanyi. Back in 1966, Polanyi wrote a book called The Tacit Dimension, which examined the ‘tacit’ dimension to human knowledge. It argued that, to a large extent, human knowledge and capability relied on skills and rulesets that are often beneath our conscious appreciation (transmitted to us via culture, tradition, evolution and so on). The thesis of the book was summarised in the slogan ‘We can know more than we can tell’.
Economist David Autor likes Polanyi’s Paradox (indeed I think he is the one who named it such). He uses it to argue that humans are likely to retain some advantages over machines for the foreseeable future. But in saying this Autor must confront the wave of technological optimism which suggests that advances in machine learning and robotics are likely to overcome Moravec and Polanyi’s paradoxes. And confront it he does. Autor argues that neither of these technological developments is as impressive as it seems and that the future is still bright for human economic relevance.
I think he might be wrong about this (though this doesn’t make the future ‘dark’ or ‘grim’). In the remainder of this post, I want to explain why.
1. Two Ways of Overcoming Polanyi’s Paradox
The first thing I need to do is provide a more detailed picture of Autor’s argument. Autor’s claim is that there are two strategies that technologists can use to overcome Polanyi’s Paradox, but if we look to the current empirical realities of these two strategies we see that they are far more limited than you might think. Consequently, the prospects of machine takeover are more limited than some are claiming, and certain forms of machine-complementary human labour are likely to remain relevant in the future.
I’m going to go through each step in this argument. I’ll start by offering a slightly more precise characterisation of Polanyi’s Paradox:
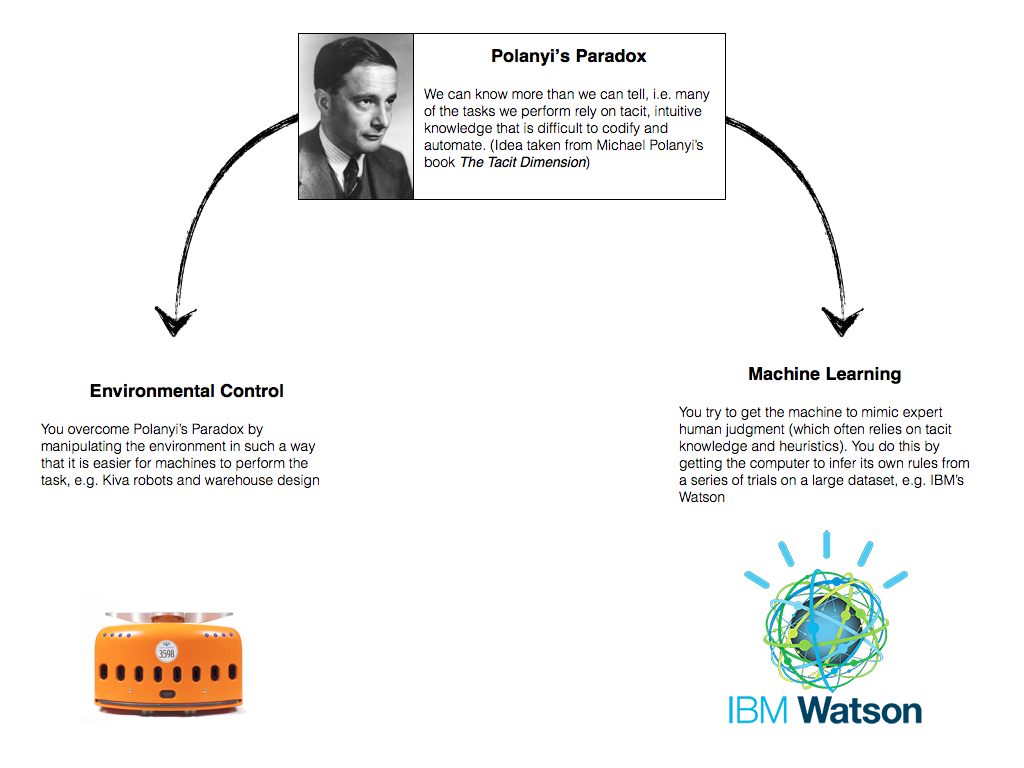
Polanyi’s Paradox: We can know more than we can tell, i.e. many of the tasks we perform rely on tacit, intuitive knowledge that is difficult to codify and automate.
I didn’t say this in the introduction but I don’t like referring to this as a ‘paradox’ since it doesn’t involve any direct self-contradiction. It is, as Autor himself notes, a constraint on the ease of automation. The question is whether this constraint can be bypassed by technological advances.
Autor claims that there are two routes around the constraint, both of which have been and currently are being employed by engineers and technologists. They are:
Environmental Control: You control and manipulate the environment in such a way that it is easier for machines to perform the task. This route around the constraint acknowledges that one of the major problems for machines is their relative inflexibility in complex environments. They tend to follow relatively simple routines and cannot easily adapt to environmental changes. One solution to this is to simplify the environment.
Machine Learning: You try to get the machine to mimic expert human judgment (which often relies on tacit knowledge and heuristics). You do this by using bottom-up machine-learning techniques instead of top-down programming. The latter require the programmer to pre-define the ruleset the computer will use when completing the task; the former gets the computer to infer its own rules from a series of trials on a large dataset.
We are all familiar with examples of both methods, even if we are occasionally unaware of them. For instance, a classic example of environmental control is the construction of roads for automobiles (or train-tracks for trains). Both have the effect of smoothing out complex environments in order to facilitate machine-based transport. Machine learning is a more recent phenomenon, but is used everywhere in the Big Data economy, from your Facebook newsfeed to Netflix recommendations.
Hopefully, you can see how both methods are used to bypass Polanyi’s Paradox: the first one does so by adapting the environment to fit the relative ‘stupidity’ of the machine; the second one does so by adapting the machine to the complexity of the environment.
2. The Limitations of Both Approaches
This brings us to the next step in Autor’s argument: the claim that neither method is as impressive or successful as we might be inclined to think. One reason why we might think Polanyi’s Paradox is a temporary roadblock is because we are impressed by the rapid advances in technology over the past thirty years, and we convinced that exponential growth in computing power, speed and so forth is likely to continue this trend. Autor doesn’t deny these advances, but is more sceptical about their long-term potential.
He defends this argument by considering some of the leading examples of environmental control and machine learning. Let’s start with environmental control and take the example of Amazon’s Kiva robots. As you may know, Amazon bought Kiva Systems in 2012 in order to take full advantage of their warehousing robots. You can see them at work in the video below.
Kiva robots work in an interesting way. They are not as physically dextrous as human workers. They cannot navigate through the traditional warehouse environment, pick items off shelves, and fill customer orders. Instead, they work on simplifying the environment and complementing the work of human collaborators. Kiva robots don’t transport or carry stock through the warehouse: they transfer shelving units. When stock comes into the warehouse, the Kiva robots bring empty shelving units to a loading area. Once in the loading area, the shelves are stocked by human workers and then transported back by the robots. When it comes time to fill an order, the process works in reverse: the robots fetch the loaded shelves, and bring them back to the humans, who pick the items off the shelf, and put them in boxes for shipping (though it should be noted that humans are assisted in this task by dispatch software that tells them which items belong in which box). The upshot is that the Kiva robots are limited to the simple task of moving shelving units across a level surface. The environment in which they work is simple.
Something similar is true of the much-lauded self-driving car (according to Autor anyway). Google’s car does not drive on roads: it drives on maps. It works by comparing real-time sensory data with maps which have been constructed to include the exact locations of obstacles and signaling systems and so forth. If there is a pedestrian, vehicle or other hazard, the car responds by ‘braking, turning and stopping’. If something truly unexpected happens (like a detour), the human has to take over. In short, the car requires simplified environments and is less adaptive than it may seem.
Autor pours similar amounts of cold water on the machine learning revolution. He is a little less example-driven in this part of his argument. He focuses on describing how machine learning works and then discusses a smattering of examples like search recommendations from Google, movie recommendations from Netflix and IBM’s Watson. I’m going to quote him in full here so you can get a sense of how he argues the point:
My general observation is that the tools [i.e. machine learning algorithms] are inconsistent: uncannily accurate at times; typically only so-so; and occasionally unfathomable… IBM’s Watson computer famously triumphed in the trivia game of Jeopardy against champion human opponents. Yet Watson also produced a spectacularly incorrect answer during its winning match. Under the category of US Cities, the question was, “Its largest airport was named for a World War II hero; its second largest, for a World War II battle.” Watson’s proposed answer was Toronto, a city in Canada. Even leading-edge accomplishments in this domain can appear somewhat underwhelming…
(Autor 2015, 26).
He goes on then to note that we are still in the early days of this technology — some are bullish about the prospects, others are not — but he thinks there may still be ‘fundamental problems’ with the systems being developed:
Since the underlying technologies — the software, hardware and training data — are all improving rapidly (Andrespouos and Tsotsos 2013), one should view these examples as prototypes rather than as mature products. Some researchers expect that as computing power rises and training databases grow, the brute force machine learning approach will approach or exceed human capabilities. Others suspect that machine learning will only ever get it right on average, while missing many of the most important and informative exceptions… Machine-learning algorithms may have fundamental problems with reasoning about “purposiveness” and intended uses, even given an arbitrarily large training database…(Grabner, Gall and Van Gool 2011). One is reminder of Carl Sagan’s (1980, p 218) remark, “If you wish to make an apple pie from scratch, you must first invent the universe.”
(Autor 2015, 26)
Again, the upshot being that the technology is more limited than we might think. He goes on to say that there will continue to be a range of skilled jobs that require human flexibility and adaptability and that they will continue to complement the rise of the machines. His go-to example is that of a medical support technician (e.g. radiology technician, nurse technician, phlebotomist). These kinds of jobs require physical dexterity, decent knowledge of mathematics and life sciences along with analytical reasoning skills. The problem, as he sees it, is not so much the continuing relevance of these jobs but the fact that our educational systems (and here he is speaking of the US) are not well set-up to provide training for these kinds of workers.
3. Is Autor Right?
As I mentioned at the outset, I’m not convinced by Autor’s arguments. There are four main reasons for this. The first is simply that I’m not sure that he’s convinced either. It seems to me that his arguments in relation machine learning are pretty weak and speculative. He acknowledges that the technology is improving rapidly but then clings to one potential limitation (the possible fundamental problem with purposiveness) to dampen enthusiasm. But even there he acknowledges that this is something that only ‘may’ be true. So, as I say, I’m not sure that even he would bet on this limitation.
Second, and more importantly, I have worries about the style of argument he employs. I agree that predictions about future technologies should be grounded in empirical realities, but there are always dangers when it comes to drawing inferences from those realities to the future. The simplest one — and one that many futurists will be inclined to push — is that Autor’s arguments may come from a failure to understand the exponential advances in technology. Autor is unimpressed by what he sees, but what he sees are advances from the relatively linear portion of an exponential growth curve. Once we get into the exponential takeoff phase, things will be radically different. Part of the problem here also has to do with how he emphasises and interprets recent developments in technology. When I look at Kiva robots, or the self-driving car or IBM’s Watson, I’m pretty impressed. I think it is amazing that technology that can do these things, particularly given that people used to say that such things were impossible for machines in the not-to-distant past. With that in mind, I think it would be foolish to make claims about future limitations based on current ones. Obviously, Autor doesn’t quite see it that way. Where I might argue that his view is based on a faulty inductive inference; he might argue (I’m putting words in his mouth, perhaps unfairly) that mine is unempirical, overly-optimistic and faith-based. If it all boils down to interpretation and best-guess inferences, who is to say who’s right?
This brings me to my third point, which is that there may be some reason to doubt Autor’s interpretation if it is based (implicitly or otherwise) on faulty assumptions about machine replacement. And I think it is. Autor seems to assume that if machines are not as flexible and adaptable as we are, they won’t fully replace us. In short, that if they are not like us, we will maintain some advantage over them. I think this ignores the advantages of non-human-likeness in robot/machine design.
This is something that Jerry Kaplan discusses quite nicely in his recent book Humans need not apply. Kaplan makes the point that you need four things to accomplish any task: (i) sensory data; (ii) energy; (iii) reasoning ability and (iv) actuating power. In human beings, all four of these things have been integrated into one biological unit (the brain-body complex). In robots, these things can be distributed across large environments: teams of smart devices can provide the sensory data; reasoning and energy can be centralised in server farms or on the ‘cloud’; and signals can be sent out to teams of actuating devices. Kaplan gives the example of a robot painter. You could imagine a robot painter as a single humanoid object, climbing ladders and applying paint with a brush; or, more likely, you could imagine it as a swarm of drones, applying paint through a spray-on nozzle, controlled by some centralised or distributed AI programme. The entire distributed system may look nothing like a human worker; but it still replaces what the human used to do. The point here is that when you look at the Kiva robots, you may be unimpressed because they don’t look or act like human workers, but they may be merely one component in a larger robotic system that does have the effect of replacing human workers. You draw a faulty inference about technological limitations by assuming the technology will be human-like.
This brings me to my final reason, which may be little more than a redressing of the previous one. In his discussion, Autor appears to treat environmental control and machine learning as independent solutions to Polanyi’s Paradox. But I don’t see why they have to be independent. Surely they could work together? Surely, we can simplify the environment and then use data from this simplified environment to train machines to be work smarter in those simplified environments? If such synergy is possible it might further loosen the constraint of Polanyi’s Paradox.
In sum, I would not like to exaggerate the potential impacts of technology on employment, but nor would I like to underestimate them. It seems to me that Autor’s argument tends toward underestimation.
This comment has been removed by a blog administrator.
ReplyDeleteThanks for the thoughtful reflection.
ReplyDelete